A few days ago Intel let the world know about a project they had been cooking up called RiverTrail. The idea is basically to extend Javascript with a "ParallelArrays" construct that you can apply certain functions to and then a compiler (in Javascript) takes your code and transforms it in to something for consumption by an OpenCL browser extension (currently only for Firefox). Naturally I was interested to see what it could do, so I went ahead and built the extension and downloaded the code to start playing.
As a test I went ahead and decided to try writing a frustum culling routine using RiverTrail, comparing it to a version written in pure Javascript and an optimized version written in C++ using intrinsics. The test consists of testing 262144 bounding spheres against a frustum 25 times over. I have uploaded the test setup here for people to try out - if you don't have the OpenCL extension for Firefox or you aren't running Firefox you will be limited to running the Javascript version. I should warn that it can take a noticeable chunk of time to create 262144 bounding spheres in a browser...
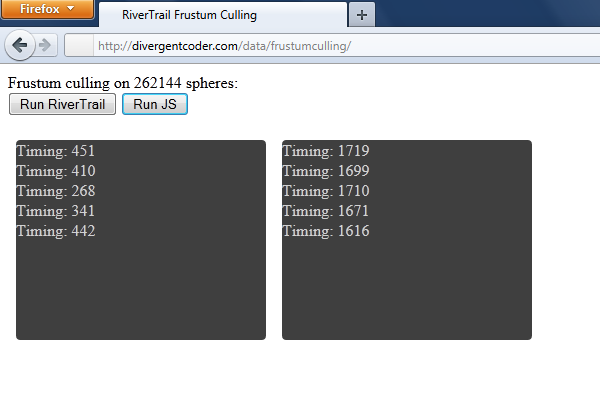
On my 2.26GHz Penryn I get the following results in Firefox 6.02:
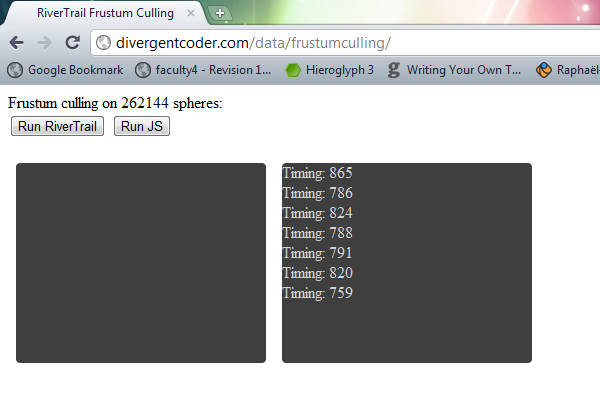
In Chrome 13.0.782.220 I get the following results:
In playing with the code I found that even though RiverTrail will cache the results of compiling your function to OpenCL, there is still a fair amount of overhead in the system. This becomes more noticeable as you decrease the number of spheres being tested; the systemic overhead becomes a greater and greater portion of the time spent as the amount of actual work you are giving the OpenCL extension decreases.
Finally, since I am afraid Mike Acton is out there somewhere with his eyes bleeding, I look at the timing for an optimized C++ frustum culling routine performing the same test. The code for this looks like this:
struct Frustum
{
__m128 x0123;
__m128 y0123;
__m128 z0123;
__m128 w0123;
__m128 x4545;
__m128 y4545;
__m128 z4545;
__m128 w4545;
};
__inline int GetVisible(const float * pts, int * res, const Frustum & frust, int num)
{
int nvis = 0;
const __m128 vzero = {0, 0, 0, 0};
for (int i=0; i<num; i+=2)
{
__m128 a = _mm_load_ps(pts + (i * 4));
__m128 b = _mm_load_ps(pts + ((i + 1) * 4));
__m128 a_xxxx = _mm_shuffle_ps(a, a, _MM_SHUFFLE(0,0,0,0));
__m128 a_yyyy = _mm_shuffle_ps(a, a, _MM_SHUFFLE(1,1,1,1));
__m128 a_zzzz = _mm_shuffle_ps(a, a, _MM_SHUFFLE(2,2,2,2));
__m128 a_wwww = _mm_shuffle_ps(a, a, _MM_SHUFFLE(3,3,3,3));
__m128 dota_0123 = _mm_add_ps(_mm_mul_ps(a_xxxx, frust.x0123), frust.w0123);
dota_0123 = _mm_add_ps(_mm_mul_ps(a_yyyy, frust.y0123), dota_0123);
dota_0123 = _mm_add_ps(_mm_mul_ps(a_zzzz, frust.z0123), dota_0123);
__m128 b_xxxx = _mm_shuffle_ps(b, b, _MM_SHUFFLE(0,0,0,0));
__m128 b_yyyy = _mm_shuffle_ps(b, b, _MM_SHUFFLE(1,1,1,1));
__m128 b_zzzz = _mm_shuffle_ps(b, b, _MM_SHUFFLE(2,2,2,2));
__m128 b_wwww = _mm_shuffle_ps(b, b, _MM_SHUFFLE(3,3,3,3));
__m128 dotb_0123 = _mm_add_ps(_mm_mul_ps(b_xxxx, frust.x0123), frust.w0123);
dotb_0123 = _mm_add_ps(_mm_mul_ps(b_yyyy, frust.y0123), dotb_0123);
dotb_0123 = _mm_add_ps(_mm_mul_ps(b_zzzz, frust.z0123), dotb_0123);
__m128 ab_xxxx = _mm_shuffle_ps(a_xxxx, b_xxxx, _MM_SHUFFLE(0,0,0,0));
__m128 ab_yyyy = _mm_shuffle_ps(a_yyyy, b_yyyy, _MM_SHUFFLE(1,1,1,1));
__m128 ab_zzzz = _mm_shuffle_ps(a_zzzz, b_zzzz, _MM_SHUFFLE(2,2,2,2));
__m128 ab_wwww = _mm_shuffle_ps(a_wwww, b_wwww, _MM_SHUFFLE(3,3,3,3));
__m128 dot_a45b45 = _mm_add_ps(_mm_mul_ps(ab_xxxx, frust.x4545), frust.w4545);
dot_a45b45 = _mm_add_ps(_mm_mul_ps(ab_yyyy, frust.y4545), dot_a45b45);
dot_a45b45 = _mm_add_ps(_mm_mul_ps(ab_zzzz, frust.z4545), dot_a45b45);
dota_0123 = _mm_cmpgt_ps(dota_0123, a_wwww);
dotb_0123 = _mm_cmpgt_ps(dotb_0123, b_wwww);
dot_a45b45 = _mm_cmpgt_ps(dot_a45b45, ab_wwww);
__m128 dota45 = _mm_shuffle_ps(dot_a45b45, vzero, _MM_SHUFFLE(0,0,0,1));
__m128 dotb45 = _mm_shuffle_ps(dot_a45b45, vzero, _MM_SHUFFLE(0,0,2,3));
__m128 resa = _mm_or_ps(dota_0123, dota45);
res[nvis] = i;
nvis += (resa.m128_i32[0] == 0 && resa.m128_i32[1] == 0 && resa.m128_i32[2] == 0 && resa.m128_i32[3] == 0) ? 1 : 0;
__m128 resb = _mm_or_ps(dotb_0123, dotb45);
res[nvis] = i + 1;
nvis += (resb.m128_i32[0] == 0 && resb.m128_i32[1] == 0 && resb.m128_i32[2] == 0 && resb.m128_i32[3] == 0) ? 1 : 0;
}
return nvis;
}This shouldn't look all that unfamiliar to people if they have seen Daniel Collin's GDC presentation - nice and fast. Testing again on my 2.26GHz Penryn, this routine clocks in at about 72ms for the same workload (262144 spheres, repeated 25 times). It comes as no surprise of course that it clocks in a fair amount faster than the Javascript version (or the RiverTrail version really), but I was curious to see what the gap would be. I will probably spend some time later with the Javascript version and see if I can extract some benefit from applying some sort of similar more data oriented approach to the code - it would also be nice to see if I can eliminate that gap between Firefox and Chrome (thanks goes out to +Chris Mills for working with me a little already on optimizing the Javascript).
In all, RiverTrail seems like a cool little library if still a little raw - I encountered a few bugs and noticed that some of the code (like filter) is still targeted at Javascript rather than OpenCL. It definitely produced faster code for this case though and I am curious to see how it evolves.